Сейчас эту информацию собирают специалисты и наносят на карту. Данные берутся из официальных источников на основе количества квартир в доме и статистике по тому, сколько человек приходится на семью в каждом муниципальном образовании. В сервисах посчитать население можно за несколько секунд: в зоне влияния, в любом районе, квартале и даже доме.
Пешеходные (см. картинку) и транспортные зоны дают возможность рассчитывать локальные объемы рынка доставки внутри городов, каннибализацию. Там, где больше населения в доме, очевидно и надо размещать пункт самовывоза товара. Все это сегодня можно сделать за секунды, потратив небольшие средства.
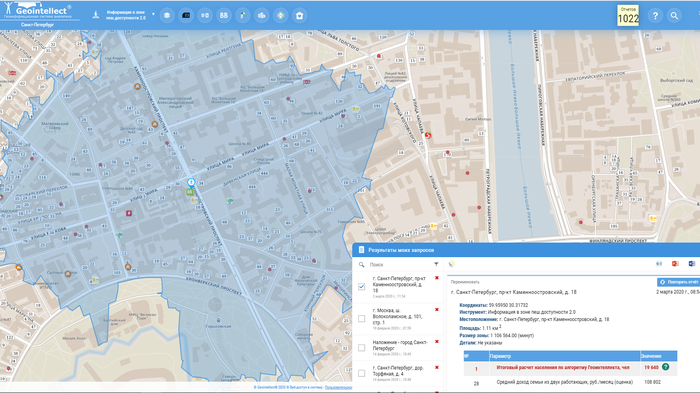
В зоне 10 минут пешком от магазина «ВкусВилл» в Санкт-Петербурге проживает 19 640 человек, или находится 7 953 домохозяйств (семей)
Заблуждение 9. Анализировать уровень доходов аудитории в небольшой локации можно с помощью государственных данных
Для оценки доходов населения внутри торговой зоны часто используют данные Росстата о зарплатах, что в корне неверно. Во-первых, данные о среднемесячной начисленной заработной плате говорят о работающем в муниципальном образовании населении, а не о проживающем, во-вторых — территориальная единица Росстата больше, чем торговая зона исследуемого объекта.
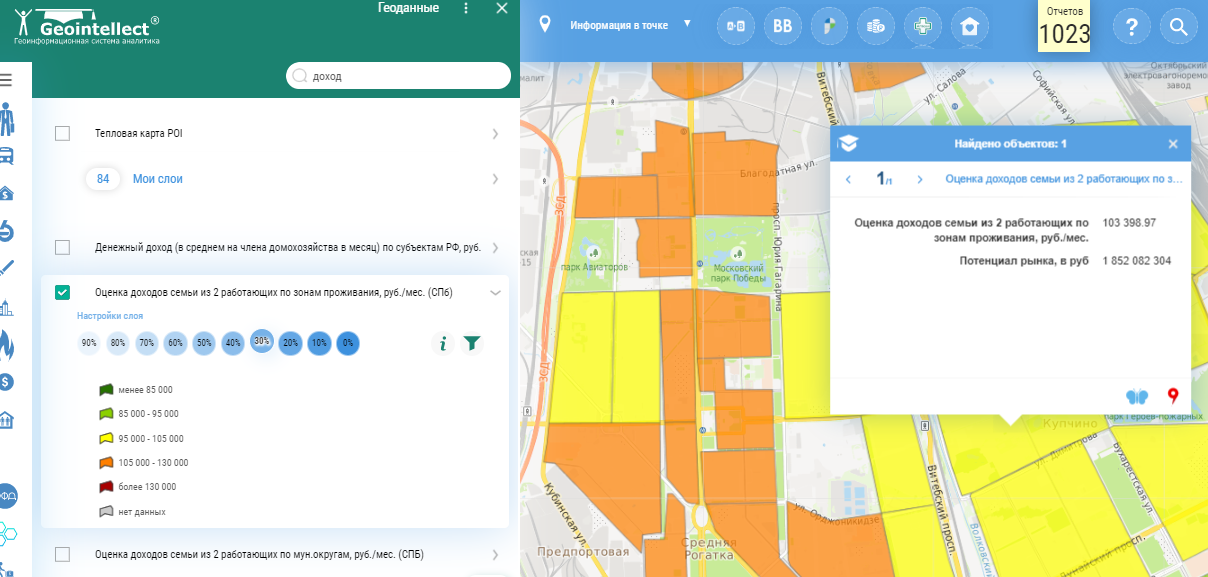
Один из распространенных методов — кластеризация территорий по типу застройки. В каждом кластере рассчитывается доход на семью из двух работающих человек. В основе лежат данные об аренде жилья. Подразумеваем, что либо семья без ребенка снимает квартиру, либо берет ипотеку — и в том, и в другом случае семья не будет тратить больше определенного дохода на семью.
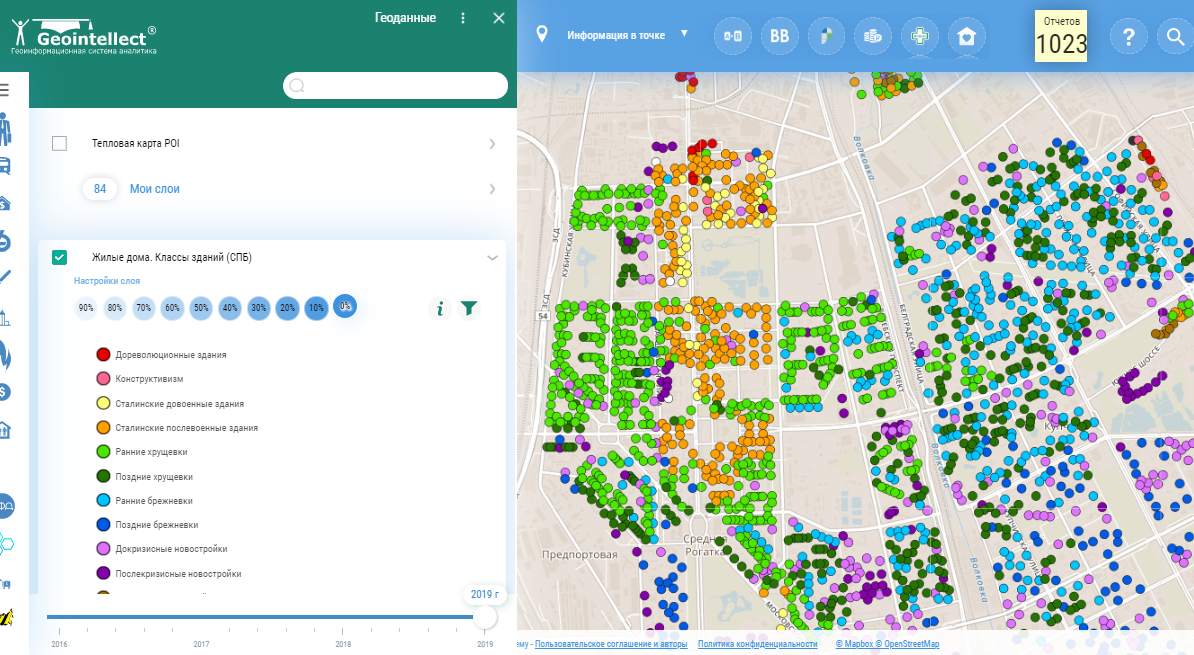
Кластеризация домов Санкт-Петербурга на основе года постройки и серии домов
Модель оценки доходов молодой семьи на основе рынка недвижимости (Московский район Санкт-Петербурга)
Есть и другие методы оценки доходов: геомоделирование на основе данных операторов мобильной связи и модели, основанные на данных о классификации жилья и арендной платы. Такие данные позволяют увидеть более реальную картину распределения доходов, которые могут влиять на некоторые форматы магазинов.

Расчет доходов в определенном возрасте в сервисе «Анализ геоданных» ПАО «МТС»
Фильтр дает возможность профилировать людей по нахождению (на работе или дома), полу, возрасту и доходам в зоне транспортной доступности от точки. Результат — на тепловой карте и графике. Так при планировании доставок, например, вы можете оценить не только объем рынка, но и целевую аудиторию в зоне доставки.
Заблуждение 8. Зачем вообще сервисы геоаналитики, если есть бесплатные государственные ресурсы?
Еще 15 лет назад Росстат, например, ограничивался только субъектами РФ и давал статистику на уровне регионов. Реже — по районам крупных городов. Пять лет назад был настроен сбор информации по муниципальным образованиям, в которые входят городские округа и сельские поселения.
Таким образом, когда вы анализируете локацию — например, 15-минутную зону от торгового центра, — вы берете не данные внутри локации, а данные по городу в целом. Исключения составляют Москва и Петербург. Такого рода информацию используют на уровне сравнения регионов, городов. Если говорить про более детальный анализ, то данные Росстата применить невозможно.
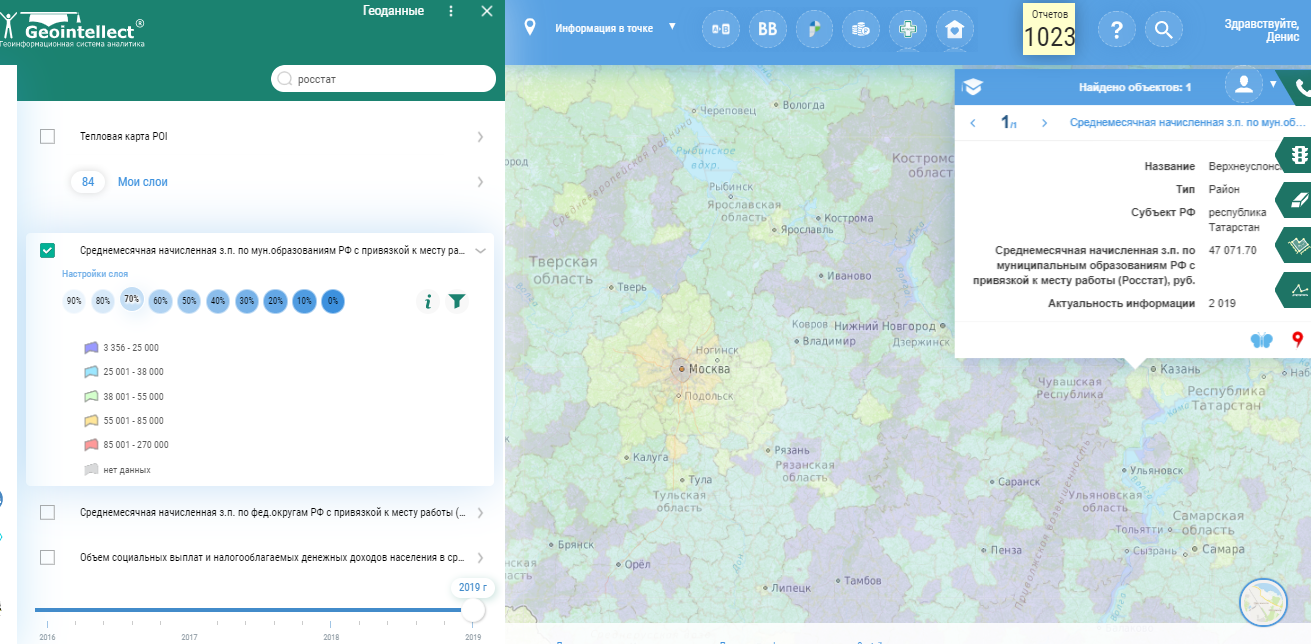
Визуализация среднесписочной зарплаты по муниципальным образованиям европейской части РФ по данным Росстата и информация по одному из муниципальных образований по Татарстану
Заблуждение 7. Можно кликнуть на карту и узнать, сколько машин проезжает за сутки в конкретной точке
Все хотят получить данные об автопотоках в конкретном сегменте улицы. Такие исследования проводятся с помощью анализа видеоданных камер наблюдения, но в масштабах всей страны это очень долго и дорого. Большинство предоставляемых данных основаны на выборочных исследованиях, значит, у них высокая погрешность.
Еще такие данные реально получить с помощью навигационных сервисов, но это могут позволить себе только крупные компании.
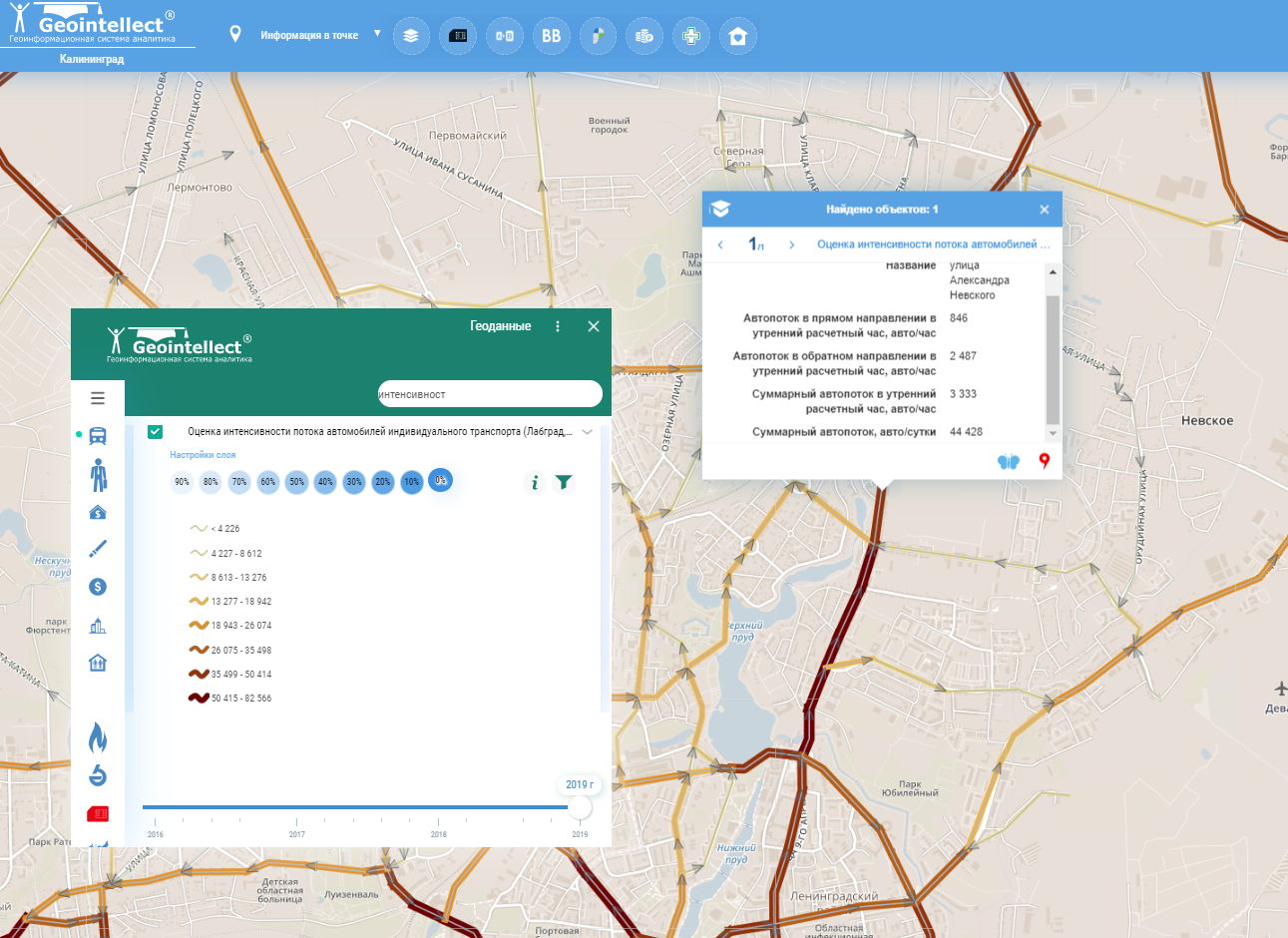
Пример визуализации числа автомобилей в Калининграде. Моделирование идет на основе замеров в определенных узлах и «продолжения» трафика автомобилей по основным улицам (без учета переулков и небольших улиц)
Заблуждение 6. Благодаря данным ОФД можно получить информацию о выручке конкурентов
54-ФЗ запрещает передавать внешним пользователям в каком-либо виде конфиденциальные данные ритейлеров. Но «грубые» данные можно использовать, чтобы изучать спрос на категории продуктов. Как это делается в геоаналитике?
Город делится на равные сетки, в которые записывается информация, рассчитанная в радиусах не менее 500 метров от объекта, и усредняется не менее чем по двум-трем точкам. Это позволяет не нарушать закон и не терять большое количество информации. Картинка «размывается», но при этом видны локации, где цена на товарные группы выше или где условного молока покупают больше.
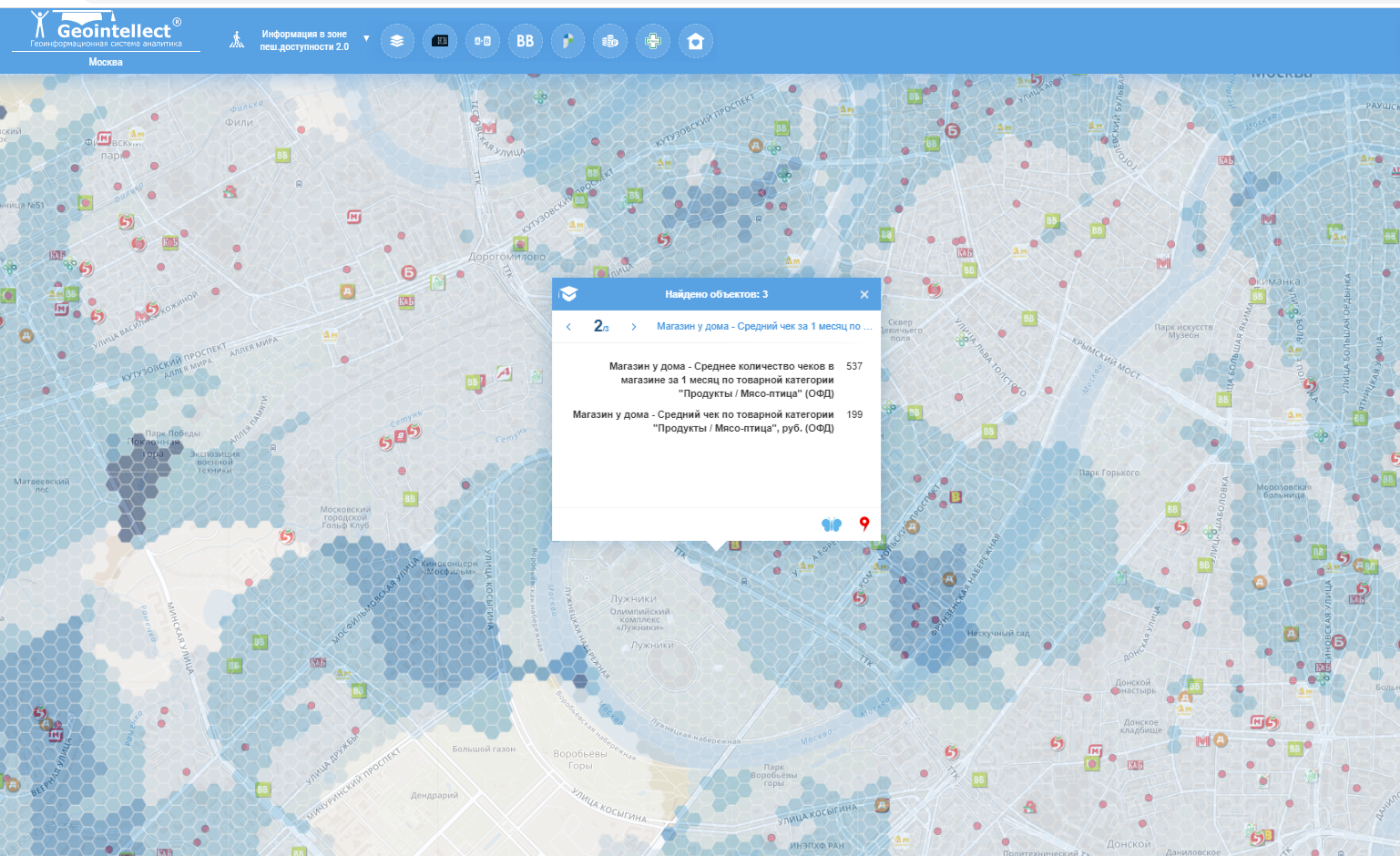
Тепловая карта средних чеков или количества чеков на основе данных ОФД «размывает» картинку и не показывает данные по конкретному магазину. (Пример данных Платформы ОФД в Москве в категории Мясо/Птица)
Заблуждение 5. Одну модель товарооборота можно использовать во всех городах
За последние пять лет мы делали предсказательные модели товарооборота 22 крупным компаниям и точно знаем, что модель, прогнозирующая товарооборот в Екатеринбурге, не должна применяться в Москве или в других городах.
Важно учитывать поведенческие особенности людей в разных городах и структуру города — это даже важнее, чем численность населения. Например, использование доставок в городах разное, их рост — тоже.
Конечно, возникает соблазн анализировать все города РФ для улучшения точности моделей, но, к сожалению, это одно из ограничений, почему не всегда ML применяется в геомаркетинге, а чаще используются эмпирические методы.
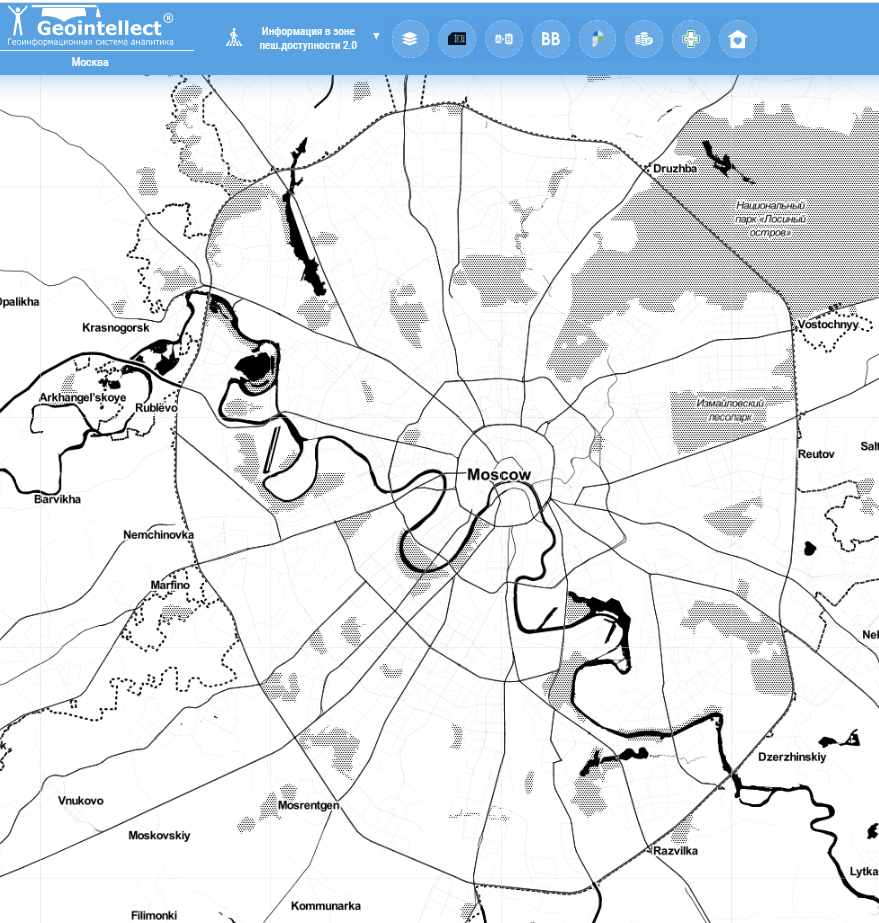
Кольцевая структура города (Москва, Ташкент)
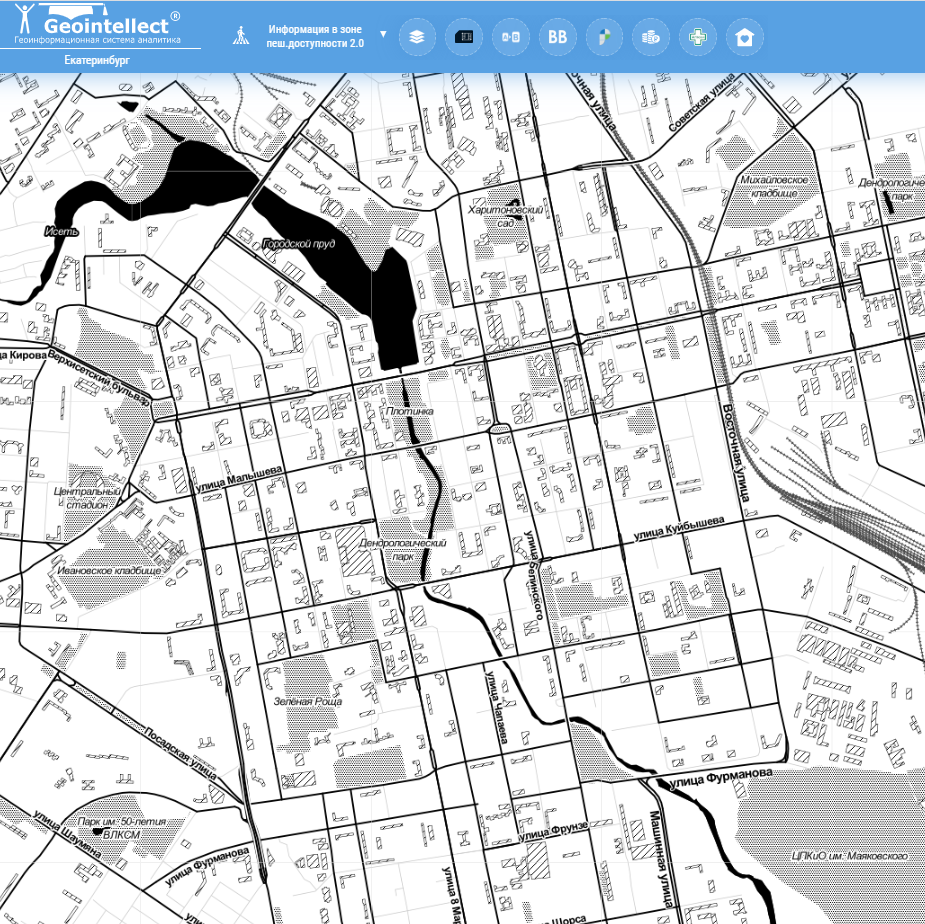
Сетчатая (Екатеринбург)
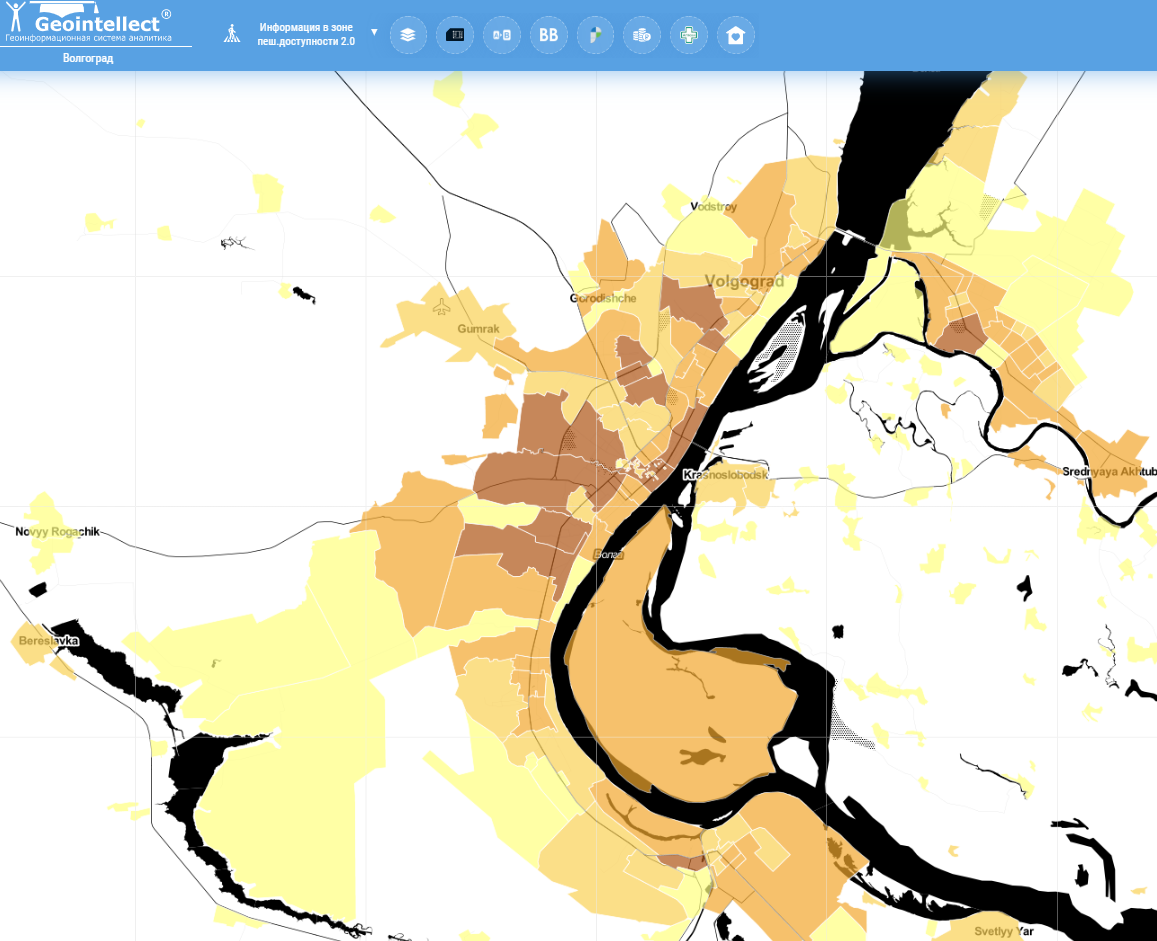
«Вытянутые» города (Хабаровск, Волгоград)
Заблуждение 4. Основанные на машинном обучении модели — это быстро и дешево
Машинное обучение часто ассоциируется со словом «быстро», но это не так. От момента, когда аналитик получает данные ритейлера о выручке, до готовой применимой модели проходит от месяца до года.
Например, чтобы получить модель прогноза товарооборота для «ВкусВилла», мы потратили порядка восьми месяцев: верифицировали данные, попробовали пять вариантов моделирования, подбирали десятки геофакторов, прежде чем получили работоспособную модель с 20% погрешности.
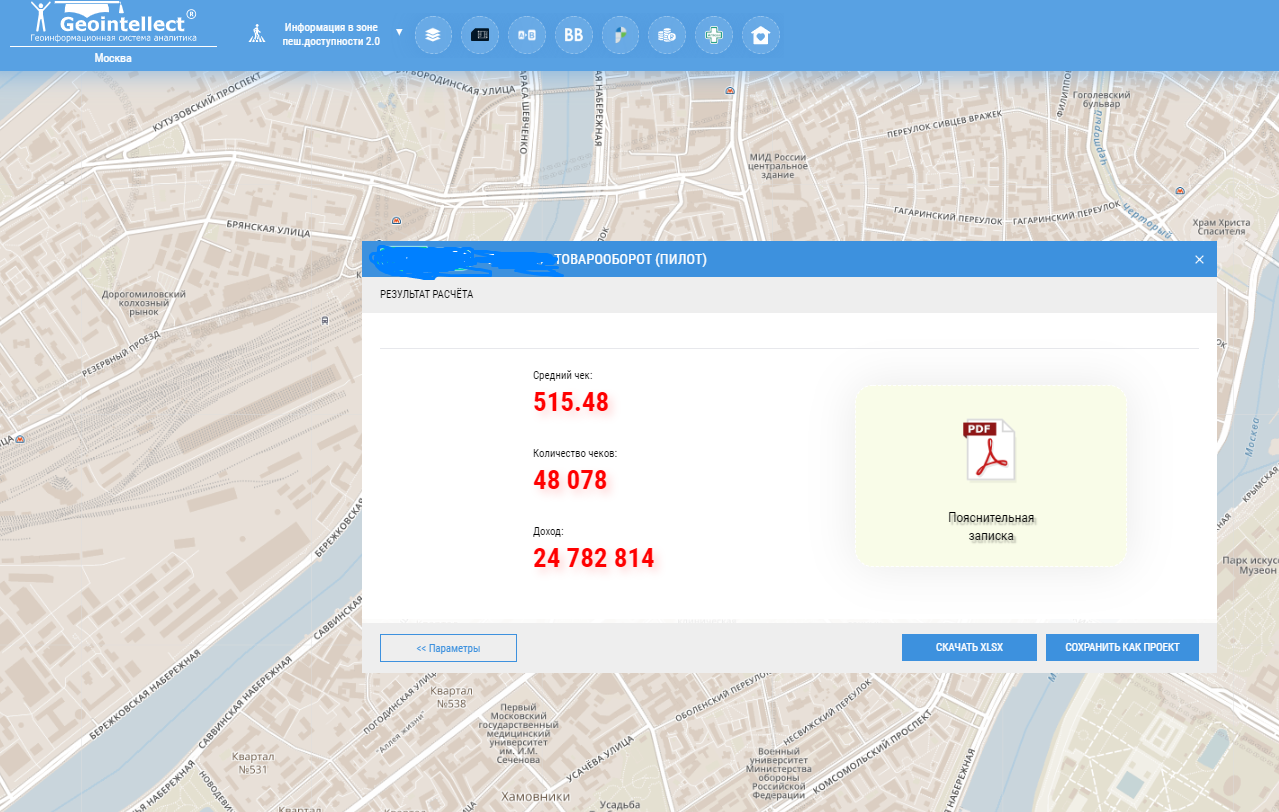
Пример прогноза среднего чека и количества чеков на основе ML одной из аптек
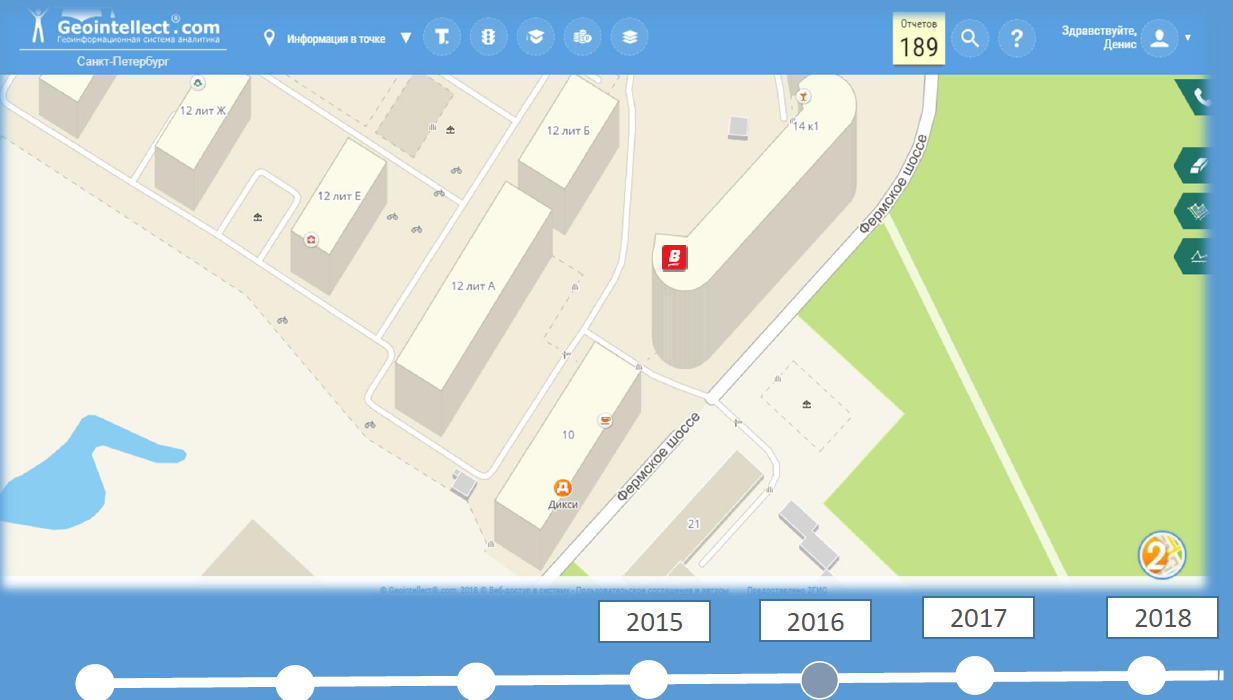
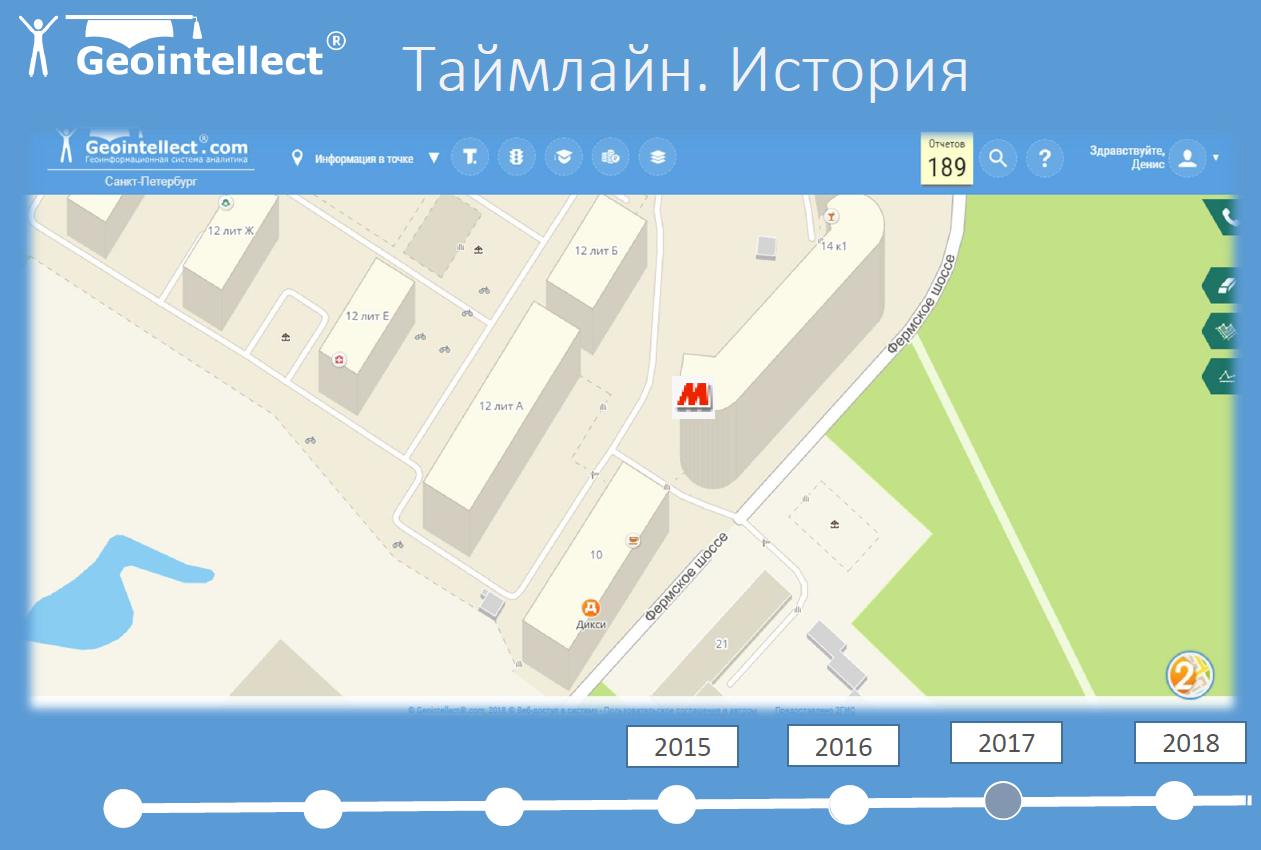
Пример изменения названия магазина на картографическом сервисе 2ГИС (API в системе «Геоинтеллект»)
Заблуждение 1. Можно кликнуть в любом месте на карте и посчитать пешеходный поток, не выходя «в поле»
Самое большое заблуждение — желание кликнуть на карту в любом месте и получить количество людей, прошедших мимо этой точки. Так это не работает, но есть семь подходов, как получать такие данные косвенно:
- Считать пассажиропоток в метро.
- Оценивать пассажиропоток на остановках или сегментах улиц по маршрутам.
- Оценивать автопоток по некоторым городам (см. выше).
- Оценивать на уровне города через моделирование вокруг объектов притяжения трафика или считать количество индикаторов массовости в зонах обслуживания.
- Использовать геоданные сотового оператора (квадраты 500 на 500 метров).
- Использовать плотность потоков смартфонов в специализированных сервисах.
- Собрать или уточнить трафик «в поле» при помощи специализированных мобильных приложений, Wi-Fi-роутеров или видеокамер.
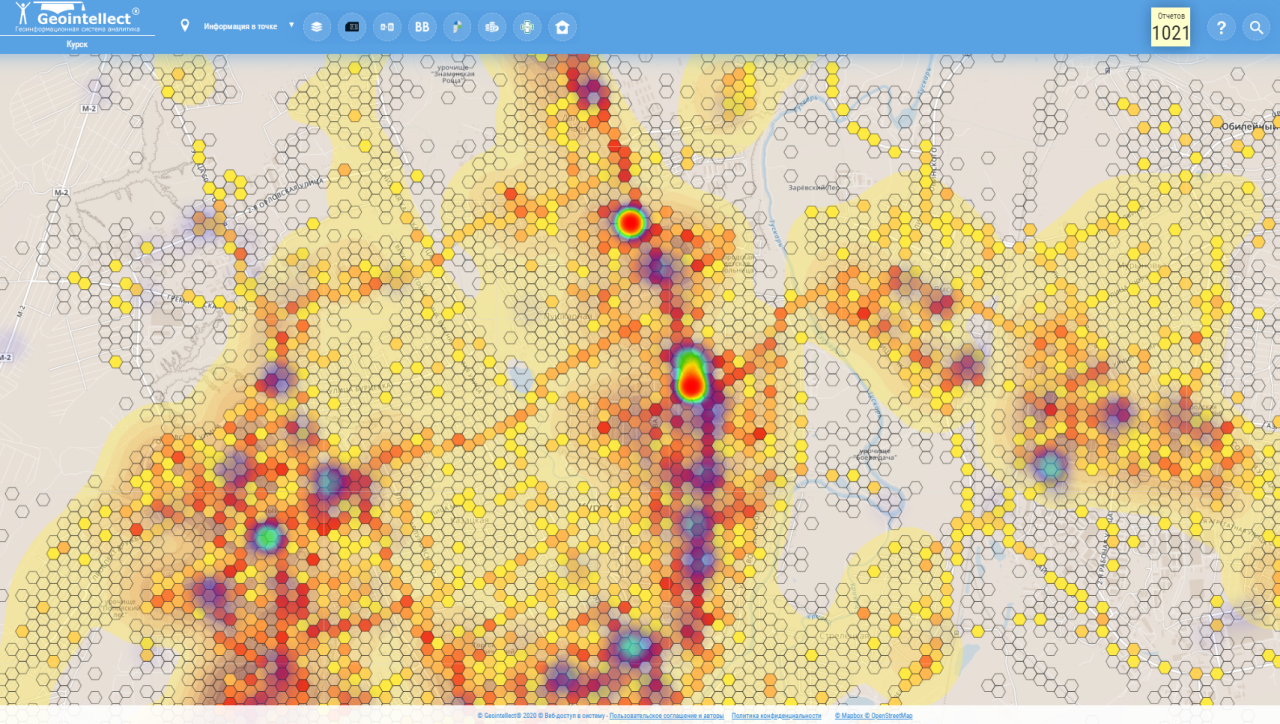
Геоданные по плотности сигналов смартфонов (Курск)
Можно обработать данные из смартфонов, но эти данные могут быть с погрешностью в локации и в количестве. Есть метод из урбанистики на основе городских объектов, которые стоят на трафике. Например, когда аптека встает у «Дикси». Зная местоположение объектов притяжения аудитории, можно получить модель притяжения населения.
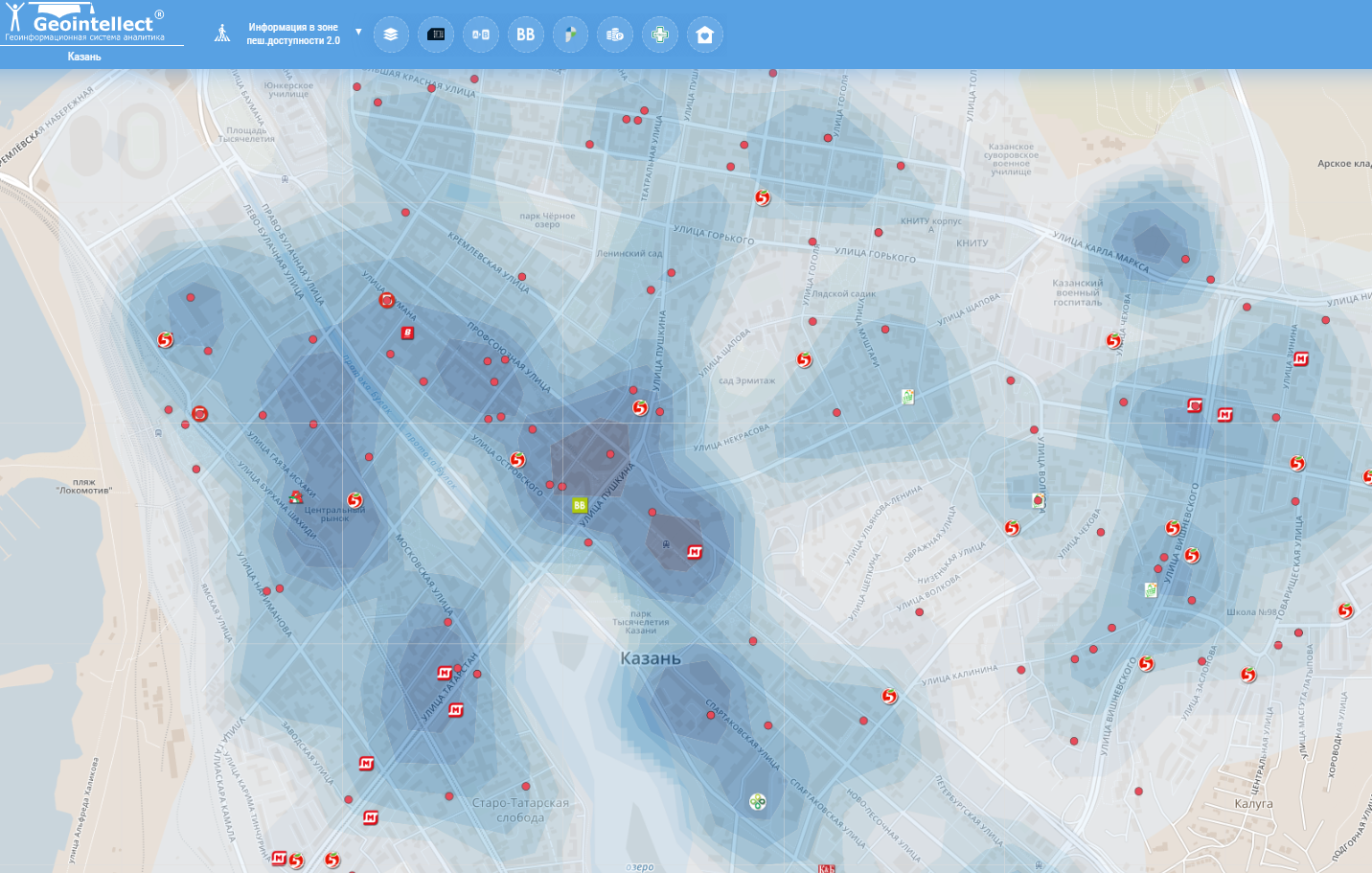
Геомодель притяжения населения (Казань)
Полевое исследование до сих пор остается важным и точным методом исследования. Оно дает цифру, которая будет тем точнее, чем дольше вы стоите на перекрестке или у входа магазин.
Но и тут может быть погрешность. Если использовать сервисы геоданных, можно упростить задачу: выбрать трафиковые места и померить «вживую». Можно скачать приложения для смартфонов по сбору данных в «полях» и считать и актуализировать геоданные.
Точечно это делать эффективнее, но надо знать, «где копать», а для этого можно провести исследование на основе различных геоданных в профессиональных сервисах, доступных на рынке.
Автор текста: Основатель Geointellect.com, генеральный директор Центра пространственных исследований